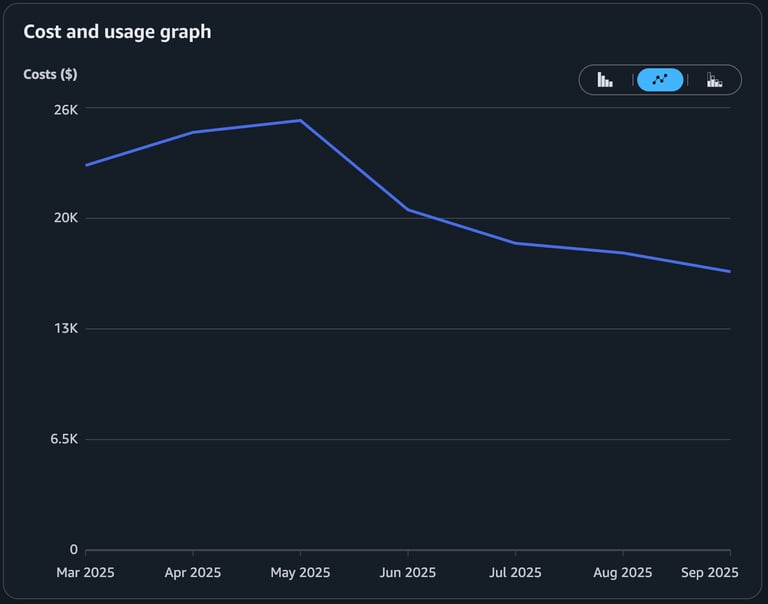
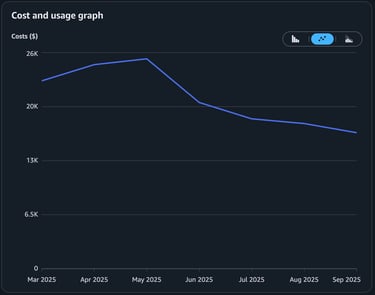
The problem most teams don't see until the bill arrives
Cloud spend rarely balloons because of one bad decision. It creeps. An oversized instance here, a forgotten volume there, logs syncing from environments nobody's watching, a dev database running 24/7 for work that happens four hours a day. Individually, each is trivial. Together, they quietly become a third of your bill.
When I took a hard look at our AWS spend across the Expertly platform, that's exactly what I found — not waste from carelessness, but waste from drift. The fix wasn't a single migration or a dramatic re-architecture. It was disciplined, systematic optimisation across every service we ran, done without disrupting a single delivery timeline.
The result: a ~33% reduction in monthly AWS costs, sustained.
How I approached it
I treated cost like a backlog — reviewed, prioritised, and worked continuously, not a fire to fight once a quarter. The work fell into a few themes:
Right-sizing what we already ran. A large share of the savings came from one question asked rigorously across every account: is this resource actually using what it's paying for? I monitored CPU and memory across EC2 instances, RDS clusters, OpenSearch, and ElastiCache nodes — and anything consistently under-utilised became a candidate to downsize, consolidate, or move to a usage-based model (for example, shifting a low-traffic dev RDS cluster to Aurora Serverless, or modernising instance families like t2 to t3 for better price-performance). The discipline was measuring before acting, and confirming with the teams who owned the workload first.
Cleaning up the drift. This is where most cloud bills quietly bleed. Unattached EBS volumes, redundant AMIs, orphaned snapshots, idle Elastic IPs, unused NAT Gateways, and resources spun up in non-primary regions and never cleaned — none of it serving a purpose, all of it billing every month. I also migrated EBS volumes from gp2 to gp3 across accounts for a straight cost reduction at equal performance. Methodically reclaiming this added up to far more than people expect.
Stopping what doesn't need to run. Not every environment needs to be on 24/7. I worked with teams to identify which dev, staging, and demo servers were genuinely needed around the clock versus what could be stopped during off-hours and started on demand — recovering meaningful EC2 spend with zero impact on the people using them.
Fixing the root cause, not just the symptom. The most satisfying savings came from working with the application teams. A slow query surfaced in RDS Performance Insights, forcing an over-provisioned cluster — add the right index, downsize the cluster. A misconfigured Lambda silently inflating CloudWatch and S3 storage. An outdated data-handling approach bloating a single table to hundreds of GB. Fix the cause, and the saving sticks — often improving performance as a bonus.
Controlling observability and storage costs. Monitoring and logging are easy to over-spend on. I reviewed CloudWatch retention policies and putMetric volume on non-prod, moved high-volume logs to S3 where CloudWatch sync wasn't needed, applied S3 lifecycle rules to shift cold data to Glacier, and disabled heavy metric exporters on dev/stage until actually required.
Committing where usage was predictable. Where consumption was stable and proven, moving from on-demand to Compute Savings Plans and Reserved Instances (across EC2, RDS, and OpenSearch) captured recurring monthly savings with zero ongoing effort.
Why it didn't slow anything down
The reason this worked is that I never treated cost-cutting as something done to the engineering teams. Every change was reviewed, confirmed with the owning team, and sequenced so it never touched a release or a client commitment. Governance, not guesswork. The savings were real because the process was careful.
And critically — I built it to stay saved. One-time clean-ups drift back. So the optimisation became an ongoing review rhythm, with tracking for things like temporary upgrades that teams forget to roll back, so the bill doesn't quietly climb again.
The takeaway
A third of a cloud bill is often recoverable — not through a heroic re-platforming, but through sustained, disciplined attention across every service, done in partnership with the people who own the workloads. The technical levers matter, but the real work is the governance: knowing what to measure, who to ask, when to act, and how to make the saving permanent.
How I Cut Monthly AWS Costs by ~33% — Without Slowing Delivery